http://deeplearning.stanford.edu/wiki/index.php/%E6%A0%88%E5%BC%8F%E8%87%AA%E7%BC%96%E7%A0%81%E7%AE%97%E6%B3%95
概述
逐层贪婪训练法依次训练网络的每一层,进而预训练整个深度神经网络。在本节中,我们将会学习如何将自编码器“栈化”到逐层贪婪训练法中,从而预训练(或者说初始化)深度神经网络的权重。
栈式自编码神经网络是一个由多层稀疏自编码器组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。对于一个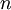 层栈式自编码神经网络,我们沿用自编码器一章的各种符号,假定用
层栈式自编码神经网络,我们沿用自编码器一章的各种符号,假定用 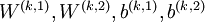 表示第
表示第 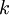 个自编码器对应的
个自编码器对应的 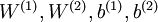 参数,那么该栈式自编码神经网络的编码过程就是,按照从前向后的顺序执行每一层自编码器的编码步骤:
参数,那么该栈式自编码神经网络的编码过程就是,按照从前向后的顺序执行每一层自编码器的编码步骤: 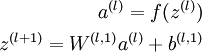 同理,栈式神经网络的解码过程就是,按照从后向前的顺序执行每一层自编码器的解码步骤:
同理,栈式神经网络的解码过程就是,按照从后向前的顺序执行每一层自编码器的解码步骤: 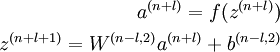 其中,
其中,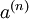 是最深层隐藏单元的激活值,其包含了我们感兴趣的信息,这个向量也是对输入值的更高阶的表示。 通过将 作为softmax分类器的输入特征,可以将栈式自编码神经网络中学到的特征用于分类问题。
是最深层隐藏单元的激活值,其包含了我们感兴趣的信息,这个向量也是对输入值的更高阶的表示。 通过将 作为softmax分类器的输入特征,可以将栈式自编码神经网络中学到的特征用于分类问题。
训练
一种比较好的获取栈式自编码神经网络参数的方法是采用逐层贪婪训练法进行训练。即先利用原始输入来训练网络的第一层,得到其参数 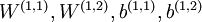 ;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数
;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数 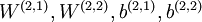 ;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练。
;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练。
作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层了。
具体实例
让我们来看个具体的例子,假设你想要训练一个包含两个隐含层的栈式自编码网络,用来进行MNIST手写数字分类(这将会是你的下一个练习)。 首先,你需要用原始输入 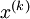 训练第一个自编码器,它能够学习得到原始输入的一阶特征表示
训练第一个自编码器,它能够学习得到原始输入的一阶特征表示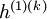 (如下图所示)。
(如下图所示)。
,都可以得到它对应的一阶特征表示。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征 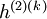 。(如下图所示) 同样,再把一阶特征输入到刚训练好的第二层稀疏自编码器中,得到每个 对应的二阶特征激活值 。接下来,你可以把这些二阶特征作为softmax分类器的输入,训练得到一个能将二阶特征映射到数字标签的模型。 如下图所示,最终,你可以将这三层结合起来构建一个包含两个隐藏层和一个最终softmax分类器层的栈式自编码网络,这个网络能够如你所愿地对MNIST数字进行分类。
。(如下图所示) 同样,再把一阶特征输入到刚训练好的第二层稀疏自编码器中,得到每个 对应的二阶特征激活值 。接下来,你可以把这些二阶特征作为softmax分类器的输入,训练得到一个能将二阶特征映射到数字标签的模型。 如下图所示,最终,你可以将这三层结合起来构建一个包含两个隐藏层和一个最终softmax分类器层的栈式自编码网络,这个网络能够如你所愿地对MNIST数字进行分类。
讨论
栈式自编码神经网络具有强大的表达能力及深度神经网络的所有优点。
更进一步,它通常能够获取到输入的“层次型分组”或者“部分-整体分解”结构。为了弄清这一点,回顾一下,自编码器倾向于学习得到能更好地表示输入数据的特征。因此,栈式自编码神经网络的第一层会学习得到原始输入的一阶特征(比如图片里的边缘),第二层会学习得到二阶特征,该特征对应一阶特征里包含的一些模式(比如在构成轮廓或者角点时,什么样的边缘会共现)。栈式自编码神经网络的更高层还会学到更高阶的特征。
举个例子,如果网络的输入数据是图像,网络的第一层会学习如何去识别边,第二层一般会学习如何去组合边,从而构成轮廓、角等。更高层会学习如何去组合更形象且有意义的特征。例如,如果输入数据集包含人脸图像,更高层会学习如何识别或组合眼睛、鼻子、嘴等人脸器官。
中英文对照
- 自编码器 Autoencoder
- 逐层贪婪训练法 Greedy layer-wise training
- 预训练 PreTrain
- 栈式自编码神经网络 Stacked autoencoder
- 微调 Fine-tuning
- 原始输入 Raw inputs
- 层次型分组 Hierarchical grouping
- 部分-整体分解 Part-whole decomposition
- 一阶特征 First-order features
- 二阶特征 Second-order features
- 更高阶特征 Higher-order features
- 激活值 Activation
中文译者
张天雷(ztl2004@gmail.com), 邓亚峰(dengyafeng@gmail.com), 许利杰(csxulijie@gmail.com)